
타이타닉 데이터 분석(2)
0. 현재 상황 파악하기
안녕하세요! 오늘은 지난 포스트에 이어서 타이타닉 데이터셋을 더 파헤쳐보도록 하겠습니다. 오늘은 데이터를 모델에 넣고 fit 시키기 전에 데이터를 모델이 읽기 쉽게 가공하고 전처리하는 것을 다룰텐데요.
먼저 데이터셋이 현재 어떻게 생겨먹었는지 한번 보겠습니다.
train.head(10)
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
| 5 | 6 | 0 | 3 | Moran, Mr. James | male | NaN | 0 | 0 | 330877 | 8.4583 | NaN | Q |
| 6 | 7 | 0 | 1 | McCarthy, Mr. Timothy J | male | 54.0 | 0 | 0 | 17463 | 51.8625 | E46 | S |
| 7 | 8 | 0 | 3 | Palsson, Master. Gosta Leonard | male | 2.0 | 3 | 1 | 349909 | 21.0750 | NaN | S |
| 8 | 9 | 1 | 3 | Johnson, Mrs. Oscar W (Elisabeth Vilhelmina Berg) | female | 27.0 | 0 | 2 | 347742 | 11.1333 | NaN | S |
| 9 | 10 | 1 | 2 | Nasser, Mrs. Nicholas (Adele Achem) | female | 14.0 | 1 | 0 | 237736 | 30.0708 | NaN | C |
train.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
이렇게 생긴 데이터셋은 어떤 모델에 적용시킨다고 해도 아마 수많은 에러와 낮은 정확도를 뱉어낼 겁니다. 지금 보이는 문제점들을 나열해보겠습니다.
Name,Sex,Embarked행의 자료형이 String(문자열)입니다. 문자열 자료형은 사람들이 읽기에는 편해도 컴퓨터가 학습하기에는 매우 나쁜 자료형입니다. 이를 숫자로 바꿔주거나, 아니면 훈련에서 아예 사용하지 않도록 할 필요가 있습니다. 또Embarked행에는NaN데이터가 딱 2개 있는 것으로 보입니다.-
Age행에NaN데이터가 드문드문 보입니다. 이NaN값을 과학적으로 채워줘야 합니다. 또 값이 다른 행에 비해 너무 큰 경향이 있습니다. 다른 행은 (0,1,2,3) 이런 식인데 Age만 (39, 50) 이런 식이라면, 훈련할 때 모델이 이 차이를 잘못된 가중치로 받아들일 가능성이 있습니다. (모델에 따라 Scaling의 중요도는 다르지만, 일반적으로는 해주는 것이 좋습니다) -
Cabin행 또한NaN데이터가 너무 많습니다. 여기는NaN항목이 너무 많아서 저 데이터 자체를 애초에 사용하는게 맞을지 판단해야 합니다. Ticket,Fare또한 자료형과 Scaling 문제가 있습니다.
이제 본격적으로 문제점들을 하나하나 고쳐나가겠습니다.
우선 train과 test 데이터셋을 잠시 묶어두겠습니다. 한꺼번에 전처리를 하기 위함입니다. 또 train과 test셋을 합친 union 데이터셋도 만들어놓겠습니다.
union = pd.concat([train.drop('Survived', axis=1), test], axis=0)
whole = [train, test, union]
1. Sex, Embarked 컬럼 숫자로 변환하기
먼저 Sex의 문자열 자료형을 숫자로 변환하겠습니다.Dictionary를 이용해서 male은 0, female은 1로 변환하겠습니다.
dic = {"male": 0, "female": 1}
for dataset in whole:
dataset['Sex'] = dataset['Sex'].map(dic)
train.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | 0 | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | 1 | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | 1 | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | 1 | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | 0 | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
2. Name 컬럼에서 Prefix 뽑아내기
다음으로는 Name 컬럼을 건드려볼겁니다. Name컬럼은 현재 문자열 자료형이고, 분류가 불가능한 상태라서 모델 훈련에 쓰기가 상당히 어렵습니다. 그래서 정규표현식을 이용해서 이름 앞에 있는 Mr, Miss, Mrs와 같은 호칭을 추출해보기로 했습니다.
for dataset in whole:
dataset['Prefix'] = dataset['Name'].str.extract(' ([A-Za-z]+)\.', expand=False)
train['Prefix'].value_counts()
Mr 517
Miss 182
Mrs 125
Master 40
Dr 7
Rev 6
Major 2
Mlle 2
Col 2
Countess 1
Mme 1
Sir 1
Lady 1
Capt 1
Don 1
Jonkheer 1
Ms 1
Name: Prefix, dtype: int64
이제 원래 데이터프레임에 있던 Name 칼럼을 삭제하고, Prefix 컬럼을 (0,1,2,3,4)로 매핑해서 남기겠습니다. Dr ~ Don 까지는 그냥 묶어서 4로 mapping하겠습니다. 이제 Prefix라는 컬럼이 맨 끝에 생긴 것을 보실 수 있습니다.
그리고 이왕 조정하는 김에, index를 PassengerId로 설정하겠습니다. 사실상 식별자 역할밖에 하지 않는 컬럼인데 저렇게 나와있으니까 불편하네요.
dic = {"Mr": 0, "Miss": 1, "Mrs": 2,
"Master": 3, "Dr": 4, "Rev": 4, "Col": 4, "Major": 4, "Mlle": 4,"Countess": 4,
"Ms": 4, "Lady": 4, "Jonkheer": 4, "Don": 4, "Dona" : 4, "Mme": 4,"Capt": 4,"Sir": 4 }
for dataset in whole:
dataset.drop('Name', axis=1, inplace=True)
dataset['Prefix'] = dataset['Prefix'].map(dic)
dataset.set_index('PassengerId', inplace=True)
whole[0]
| Survived | Pclass | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | Prefix | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| PassengerId | |||||||||||
| 1 | 0 | 3 | 0 | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S | 0 |
| 2 | 1 | 1 | 1 | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C | 2 |
| 3 | 1 | 3 | 1 | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S | 1 |
| 4 | 1 | 1 | 1 | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S | 2 |
| 5 | 0 | 3 | 0 | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 887 | 0 | 2 | 0 | 27.0 | 0 | 0 | 211536 | 13.0000 | NaN | S | 4 |
| 888 | 1 | 1 | 1 | 19.0 | 0 | 0 | 112053 | 30.0000 | B42 | S | 1 |
| 889 | 0 | 3 | 1 | NaN | 1 | 2 | W./C. 6607 | 23.4500 | NaN | S | 1 |
| 890 | 1 | 1 | 0 | 26.0 | 0 | 0 | 111369 | 30.0000 | C148 | C | 0 |
| 891 | 0 | 3 | 0 | 32.0 | 0 | 0 | 370376 | 7.7500 | NaN | Q | 0 |
891 rows × 11 columns
우리가 Prefix로 추출한 컬럼이 얼마나 성공적이었는지 확인하기 위해 Prefix에 대한 그래프를 한번 그려보겠습니다.
survived = train[train['Survived'] == 1]['Prefix'].value_counts()
dead = train[train['Survived'] == 0]['Prefix'].value_counts()
df = pd.DataFrame([survived, dead])
df.index = ['Survived', 'Dead']
df.plot(kind='bar', stacked=True)
<matplotlib.axes._subplots.AxesSubplot at 0x7f7438c73f10>
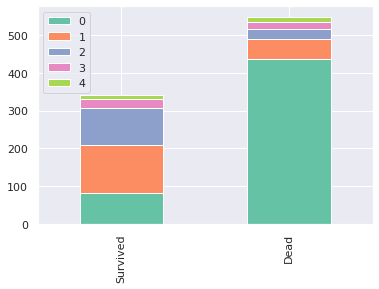
최소한 Prefix값이 (0,1,2)인건 생존율에 명확한 차이가 있음을 확인할 수 있습니다. 괜찮은 feature를 추출한 것 같습니다.
3. Age의 NaN값 채우기
다음으로는 Age 컬럼에 있는 NaN들을 채워보도록 하겠습니다.
유실된 Age 값을 어떻게 과학적으로 채워넣을 수 있을까요?
보통 아래와 같은 방법들이 있습니다.
-
NaN 값에 평균을 대입한다
-
NaN 값이 존재하는 row 자체를 데이터에서 배제한다.
-
NaN 값을 해당 열의 윗열 데이터나, 아랫열 데이터에서 가져온다 (ffill, bfill)
여기서 해볼 방법은, NaN값에 평균을 대입하되, 조금 더 과학적으로 평균을 넣어보겠습니다. 아까 구했던 Prefix에는 Miss, Mr, Mrs 등 여러 호칭들이 있었는데, 그 호칭들과 나이는 어느 정도의 상관관계가 있을 것입니다. 그래서 전체 평균을 NaN에 대입하기보다는, 각 Prefix의 평균을 해당 Prefix를 가진 NaN값에 대입시켜 줄 겁니다.
그리고 평균은 신뢰도를 높이기 위해 train과 test를 합친 union 데이터셋에서 가져오겠습니다.
코드로 보여드리겠습니다.
for dataset in whole:
dataset["Age"].fillna(union.groupby("Prefix")["Age"].transform("mean"), inplace=True)
train.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 891 entries, 1 to 891
Data columns (total 11 columns):
Survived 891 non-null int64
Pclass 891 non-null int64
Sex 891 non-null int64
Age 891 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
Prefix 891 non-null int64
dtypes: float64(2), int64(6), object(3)
memory usage: 83.5+ KB
확인해보시면 Age 칼럼의 NaN 값들이 모두 채워진 것을 확인할 수 있습니다.
4. Age 컬럼 Binning 하기
이제 Age 값을 binning 해볼건데요. binning은 쉽게 말하면 카테고리화 하는겁니다. 1 ~ 100까지의 숫자가 무작위로 퍼져 있다면, 1 ~ 10, 11 ~ 20, 21 ~ 30 이런 식으로 분류하는거죠. 이렇게 분류하면 Scaling의 효과도 있고, 혹시 데이터에 특정한 숫자가 비정상적으로 많다던가 하는 비정상적인 경향성을 어느 정도 해소할 수 있습니다.
먼저 Age의 현재 사분위수를 확인해보겠습니다.
union['Age'].describe()
count 1309.000000
mean 29.907391
std 13.197710
min 0.170000
25% 21.774238
50% 30.000000
75% 36.000000
max 80.000000
Name: Age, dtype: float64
저는 간단하게 저 사분위수에 맞춰서 binning을 해보도록 하겠습니다.
- 0 ~ 22세
- 22 초과 ~ 29세
- 29세 초과 ~ 35세
- 35세 초과
qcut을 이용하면 정해진 비율대로 binning을 편하게 할 수 있습니다.코드를 보여드리겠습니다.
for dataset in whole:
dataset['AgeCut'] = pd.qcut(dataset['Age'], 4, labels=[0,1,2,3])
dataset.drop('Age', axis=1, inplace=True)
train.head()
| Survived | Pclass | Sex | SibSp | Parch | Ticket | Fare | Cabin | Embarked | Prefix | AgeCut | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| PassengerId | |||||||||||
| 1 | 0 | 3 | 0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S | 0 | 1 |
| 2 | 1 | 1 | 1 | 1 | 0 | PC 17599 | 71.2833 | C85 | C | 2 | 3 |
| 3 | 1 | 3 | 1 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S | 1 | 1 |
| 4 | 1 | 1 | 1 | 1 | 0 | 113803 | 53.1000 | C123 | S | 2 | 2 |
| 5 | 0 | 3 | 0 | 0 | 0 | 373450 | 8.0500 | NaN | S | 0 | 2 |
보시면 맨 끝에 AgeCut이라는 행이 생겼고, 0,1,2,3 으로 구분되어 있는 것을 확인하실 수 있습니다. 원래 있던 Age 행은 drop해버렸습니다. 어차피 모델 훈련에 사용하지 않을 것이기 때문이죠.
5. Fare 행 NaN 채우고 binning 하기
Fare 행도 Age 행과 마찬가지로 몇개의 NaN을 가지고 있으며, 값이 다른 컬럼들과 너무 달라서 Scaling이 필요합니다. Age 행에서는 나이와 가장 관련 있었던 Prefix 행과 결합해서 NaN을 채웠죠? 여기서는 Fare과 가장 관련있어 보이는 Pclass별로 그룹을 나누어 NaN을 채우겠습니다.
for dataset in whole:
dataset["Fare"].fillna(union.groupby("Pclass")["Fare"].transform("mean"), inplace=True)
union.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 1309 entries, 1 to 1309
Data columns (total 10 columns):
Pclass 1309 non-null int64
Sex 1309 non-null int64
SibSp 1309 non-null int64
Parch 1309 non-null int64
Ticket 1309 non-null object
Fare 1309 non-null float64
Cabin 295 non-null object
Embarked 1307 non-null object
Prefix 1309 non-null int64
AgeCut 1309 non-null category
dtypes: category(1), float64(1), int64(5), object(3)
memory usage: 143.7+ KB
Fare행에 있던 NaN값이 사라졌습니다! 이제 마찬가지로 여기서도 Binning을 해주겠습니다. Age를 Binning 할때랑 같은 방식으로 하니까 설명은 위에서 참고해주세요!
for dataset in whole:
dataset['FareCut'] = pd.qcut(dataset['Fare'], 4, labels=[0,1,2,3])
dataset.drop('Fare', axis=1, inplace=True)
train.head()
| Survived | Pclass | Sex | SibSp | Parch | Ticket | Cabin | Embarked | Prefix | AgeCut | FareCut | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| PassengerId | |||||||||||
| 1 | 0 | 3 | 0 | 1 | 0 | A/5 21171 | NaN | S | 0 | 1 | 0 |
| 2 | 1 | 1 | 1 | 1 | 0 | PC 17599 | C85 | C | 2 | 3 | 3 |
| 3 | 1 | 3 | 1 | 0 | 0 | STON/O2. 3101282 | NaN | S | 1 | 1 | 1 |
| 4 | 1 | 1 | 1 | 1 | 0 | 113803 | C123 | S | 2 | 2 | 3 |
| 5 | 0 | 3 | 0 | 0 | 0 | 373450 | NaN | S | 0 | 2 | 1 |
6. Ticket, Cabin 행 drop하여 차원 축소하기
이제 Ticket, Cabin 행을 다뤄보겠습니다. 그런데 생각해보면, 굳이 Ticket, Cabin이라는 행이 필요할까요? Kaggle 이 제공한 Data Dictionary를 참고하면 Ticket은 그저 티켓의 일련번호이고, Cabin은 방의 번호입니다.
우선 티켓의 일련번호는 모델이 학습해봤자 아무 쓸데가 없을 것 같습니다. 티켓의 일련번호는 Drop해도 될 것 같습니다.
방 번호는 어떨까요? 방 번호는 어쩌면 생존 확률과 연관이 있을지도 모릅니다. 하지만 값의 개수에 문제가 있습니다. 코드를 보시죠.
union.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 1309 entries, 1 to 1309
Data columns (total 10 columns):
Pclass 1309 non-null int64
Sex 1309 non-null int64
SibSp 1309 non-null int64
Parch 1309 non-null int64
Ticket 1309 non-null object
Cabin 295 non-null object
Embarked 1307 non-null object
Prefix 1309 non-null int64
AgeCut 1309 non-null category
FareCut 1309 non-null category
dtypes: category(2), int64(5), object(3)
memory usage: 135.0+ KB
보시면, train과 test 합쳐서 데이터가 1309개인데, Cabin은 데이터가 295개밖에 존재하지 않습니다. 설령 저 295개의 데이터 안에서 경향성을 찾는다고 해도, 295개의 데이터에서 찾은 경향성을 1309개의 데이터에 일반화시켜 NaN을 채워넣는 것은 그리 신뢰도가 높을 것 같지 않습니다. 그래서 저는 과감하게 Ticket행과 Cabin행을 이번 데이터에서 제외하기로 했습니다.
for dataset in whole:
dataset.drop('Ticket', axis=1, inplace=True)
dataset.drop('Cabin', axis=1, inplace=True)
7. Embarked 행의 NaN drop 후 자료형 변환하기
이제 슬슬 끝이 보입니다!
이번에는 Embarked행을 다뤄볼 겁니다. 아까 이 컬럼에 NaN값이 있었던 것을 기억하시나요? 그런데 아래의 test.isnull().sum()과 train.isnull().sum()를 보면, NaN 값은 train 데이터셋에만 두개 있다는 것을 확인할 수 있습니다. 그래서 저는 그냥 저 2개를 dropna()를 활용해서 없애버리기로 했습니다. 허허
test.isnull().sum()
Pclass 0
Sex 0
SibSp 0
Parch 0
Embarked 0
Prefix 0
AgeCut 0
FareCut 0
dtype: int64
train.isnull().sum()
Survived 0
Pclass 0
Sex 0
SibSp 0
Parch 0
Embarked 2
Prefix 0
AgeCut 0
FareCut 0
dtype: int64
train = train.dropna(axis=0)
test = test.dropna(axis=0)
train.isnull().sum()
Survived 0
Pclass 0
Sex 0
SibSp 0
Parch 0
Embarked 0
Prefix 0
AgeCut 0
FareCut 0
dtype: int64
NaN값이 모두 사라진 것을 보실 수 있습니다!
이제 정말 마지막으로 Embarked행에 mapping만 하면 됩니다.
- S : 0
- C : 1
- Q : 2
로 매핑하겠습니다.
dic = {"S": 0, "C": 1, "Q": 2}
train.loc[:, 'Embarked'] = train.loc[:, 'Embarked'].map(dic)
test.loc[:, 'Embarked'] = test.loc[:, 'Embarked'].map(dic)
이제 정말 끝났습니다! 전처리가 완료된 데이터를 확인해볼까요?
train
| Survived | Pclass | Sex | SibSp | Parch | Embarked | Prefix | AgeCut | FareCut | |
|---|---|---|---|---|---|---|---|---|---|
| PassengerId | |||||||||
| 1 | 0 | 3 | 0 | 1 | 0 | 0 | 0 | 1 | 0 |
| 2 | 1 | 1 | 1 | 1 | 0 | 1 | 2 | 3 | 3 |
| 3 | 1 | 3 | 1 | 0 | 0 | 0 | 1 | 1 | 1 |
| 4 | 1 | 1 | 1 | 1 | 0 | 0 | 2 | 2 | 3 |
| 5 | 0 | 3 | 0 | 0 | 0 | 0 | 0 | 2 | 1 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 887 | 0 | 2 | 0 | 0 | 0 | 0 | 4 | 1 | 1 |
| 888 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 2 |
| 889 | 0 | 3 | 1 | 1 | 2 | 0 | 1 | 0 | 2 |
| 890 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 2 |
| 891 | 0 | 3 | 0 | 0 | 0 | 2 | 0 | 2 | 0 |
889 rows × 9 columns
test
| Pclass | Sex | SibSp | Parch | Embarked | Prefix | AgeCut | FareCut | |
|---|---|---|---|---|---|---|---|---|
| PassengerId | ||||||||
| 892 | 3 | 0 | 0 | 0 | 2 | 0 | 2 | 0 |
| 893 | 3 | 1 | 1 | 0 | 0 | 2 | 3 | 0 |
| 894 | 2 | 0 | 0 | 0 | 2 | 0 | 3 | 1 |
| 895 | 3 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
| 896 | 3 | 1 | 1 | 1 | 0 | 2 | 0 | 1 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 1305 | 3 | 0 | 0 | 0 | 0 | 0 | 2 | 1 |
| 1306 | 1 | 1 | 0 | 0 | 1 | 4 | 3 | 3 |
| 1307 | 3 | 0 | 0 | 0 | 0 | 0 | 3 | 0 |
| 1308 | 3 | 0 | 0 | 0 | 0 | 0 | 2 | 1 |
| 1309 | 3 | 0 | 1 | 1 | 1 | 3 | 0 | 2 |
418 rows × 8 columns
8. 마치며
오늘은 정말 귀찮으면서도 중요한 작업인 Feature Engineering 을 해봤습니다. 사실 이 데이터 전처리 작업은 사람마다 하는 방식이 다를 수 있습니다. 같은 데이터를 가지고 시작하더라도 나중에는 미묘한 차이가 있을 수 있다는 것이죠. 데이터 처리에 정답은 없습니다. 어떤 데이터에서는 A라는 사람의 판단이 옳을 수도 있고, 어떤 데이터에서는 B라는 사람의 판단이 옳을 수도 있습니다.
다음 포스팅에서는 이렇게 전처리한 데이터를 바탕으로 정말 모델에 적용시켜서 훈련하고 결과까지 내보도록 하겠습니다. 감사합니다!
댓글남기기