
타이타닉 데이터 분석(1)
0. 소개
안녕하세요! 오늘은 Kaggle의 Titanic 데이터셋을 활용해서 실제 데이터 분석을 해보려고 합니다. Titanic 데이터셋은 캐글의 대표적인 데이터셋으로, Kaggle 홈페이지 상으로 무려 20000명 정도가 참여한 유명한 문제입니다!
1. 문제 정의
오늘 사용할 데이터셋은 캐글에 있는 타이타닉 데이터셋입니다! 타이타닉을 모르시는 분은 없으리라 생각하지만, 몰입감을 위해 타이타닉에 대한 설명을 추가하겠습니다.
타이타닉(Titanic)은 영국의 화이트 스타 라인이 운영한 북대서양 횡단 여객선이다. 1912년 4월 10일 영국의 사우샘프턴을 떠나 미국의 뉴욕으로 향하던 첫 항해 중에 4월 15일 빙산과 충돌하여 침몰하였다. 배에는 승객들을 태울 충분한 구명보트가 없었고, 타이타닉의 침몰로 2,224명의 승객 중 1,502명이 사망하였다.
이 문제에서는 타이타닉 사건때 배에 있었던 승객들 명단이 데이터셋으로 주어집니다. (실제 명단인지는 저도 잘 모르겠습니다)
문제의 목표는 다음과 같습니다.
타이타닉에서 살아남을 수 있는 승객을 예측하기
이 Competition에 참여하는 사람들은, 주어진 훈련 데이터를 이용해서 데이터를 분석하고 경향성을 찾아 성공적인 예측을 해내야 합니다. 이제 본격적으로 데이터 분석을 시작해보겠습니다.
2. 데이터 불러오기
먼저 필요한 라이브러리들을 import합니다. 위의 pandas, numpy는 데이터프레임과 연산을 위한 라이브러리이고, matplotlib과 seaborn은 charting을 위해 추가했습니다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
import seaborn as sns
train = pd.read_csv('kaggle/titanic/train.csv')
test = pd.read_csv('kaggle/titanic/test.csv')
Kaggle에서 직접 타이타닉 데이터셋을 보시면 아시겠지만, 데이터셋은 test 데이터와 train 데이터 두 가지로 나뉘어 있습니다. 데이터셋의 이름처럼, train 데이터는 모델 훈련에 쓰이고, test 데이터는 모델 검증에 쓰이게 됩니다. csv로 깔끔하게 자료가 정리되어 있어 pandas의 read_csv()를 쓰면 너무나도 깔끔하게 데이터를 불러올 수 있습니다.
3. 데이터 분석하기
이제 train.head(), test.head()를 이용해서 데이터가 어떤 식으로 주어지는지 살펴보겠습니다. 데이터프레임에 .head()를 쓰면 상위 5개의 row만 잘라서 볼 수 있습니다.
데이터에 대한 Kaggle의 설명(사이트에 나와있습니다)를 번역해서 첨부하겠습니다.
Data Dictionary
- Survived : 0 = 사망, 1 = 생존
- Pclass : 1 = 1등석, 2 = 2등석, 3 = 3등석
- Sex : male = 남성, female = 여성
- Age : 나이
- SibSp : 타이타닉 호에 동승한 자매 / 배우자의 수
- Parch : 타이타닉 호에 동승한 부모 / 자식의 수
- Ticket : 티켓 번호
- Fare : 승객 요금
- Cabin : 방 호수
- Embarked : 탑승지, C = 셰르부르, Q = 퀸즈타운, S = 사우샘프턴
train.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
test.head()
| PassengerId | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 892 | 3 | Kelly, Mr. James | male | 34.5 | 0 | 0 | 330911 | 7.8292 | NaN | Q |
| 1 | 893 | 3 | Wilkes, Mrs. James (Ellen Needs) | female | 47.0 | 1 | 0 | 363272 | 7.0000 | NaN | S |
| 2 | 894 | 2 | Myles, Mr. Thomas Francis | male | 62.0 | 0 | 0 | 240276 | 9.6875 | NaN | Q |
| 3 | 895 | 3 | Wirz, Mr. Albert | male | 27.0 | 0 | 0 | 315154 | 8.6625 | NaN | S |
| 4 | 896 | 3 | Hirvonen, Mrs. Alexander (Helga E Lindqvist) | female | 22.0 | 1 | 1 | 3101298 | 12.2875 | NaN | S |
확인해보니 train 데이터와 test 데이터는 보기에 큰 차이가 없습니다.
하지만 눈치채셨나요? test 데이터에는 Survived 행이 존재하지 않습니다. 조금만 생각해보면 당연하다는 것을 알 수 있습니다. test 데이터에까지 Survived가 다 나와 있으면 문제의 답을 알려주는 것과 마찬가지일 테니까요. 우리는 궁극적으로 저 test 데이터셋의 Survived 행을 예측해서 Kaggle 에 제출하면 됩니다.
그런데 데이터셋을 보니 중간중간 NaN 값들이 보입니다. NaN은 Not a Number를 의미합니다. 사실상 값이 유실되었다고 봐도 무방합니다. 이런 유실된 값들은 나중에 모델을 만들고 훈련시킬 때 적절한 조치를 취해주어야 합니다. 이것을 Feature Engineering 이라고 하는데, 이것은 다음 글에서 이어서 설명하겠습니다.
유실된 값들이 얼마나 있는지, 그리고 데이터의 전체적인 구조를 보기 위해 .info() 메써드를 써보겠습니다.
train.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
test.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 418 entries, 0 to 417
Data columns (total 11 columns):
PassengerId 418 non-null int64
Pclass 418 non-null int64
Name 418 non-null object
Sex 418 non-null object
Age 332 non-null float64
SibSp 418 non-null int64
Parch 418 non-null int64
Ticket 418 non-null object
Fare 417 non-null float64
Cabin 91 non-null object
Embarked 418 non-null object
dtypes: float64(2), int64(4), object(5)
memory usage: 36.0+ KB
.info() 메써드를 호출해보니, train 데이터는 891행, test 데이터는 418행임을 알 수 있습니다. 그 중 Age와 Cabin만 데이터 개수가 다른 것을 보아, Age와 Cabin을 제외하면 NaN 값은 더 없는 것으로 보입니다. 없는 값 과학적으로 채워넣으려면 귀찮은데 다행입니다. 물론 값이 없는 승객은 그냥 데이터에서 빼버려도 되지만, 이 문제는 데이터가 충분하지 않기 때문에 데이터 하나하나가 소중합니다.
이제부턴 시각화를 하면서 특성별로 분석을 해보겠습니다.
분석을 편하게 하기 위해, 함수를 하나 만들었습니다.
각 특성을 인수로 함수를 호출하면 그에 따른 표를 그리도록 했습니다.
# 그래프를 예쁘게 그리기 위해 추가했습니다
plt.style.use('ggplot')
sns.set()
sns.set_palette("Set2")
def chart(dataset, feature):
survived = dataset[dataset['Survived'] == 1][feature].value_counts()
dead = dataset[dataset['Survived'] == 0][feature].value_counts()
df = pd.DataFrame([survived, dead])
df.index = ['Survived', 'Dead']
df.plot(kind='bar', stacked=True)
먼저 Pclass에 대한 그래프를 보겠습니다.
chart(train, 'Pclass')
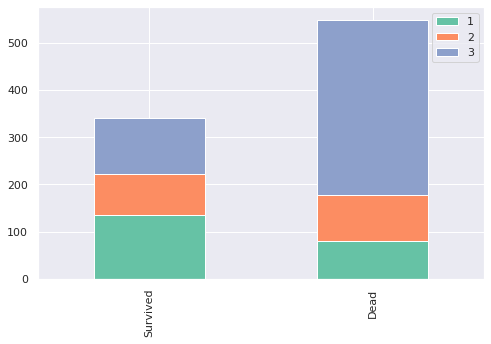
보시면 1등석에 있던 승객들은 오히려 사망한 사람보다 생존한 사람이 많고, 2등석은 대략 생존율이 50%정도 되는 것 같습니다. 반면 3등석은 생존한 사람보다 사망한 사람이 훨씬 많습니다. 이걸 보아 Pclass라는 특성은 승객의 생사를 예측하는 데에 큰 영향을 끼친다는 것을 확인할 수 있습니다. 지금 이렇게 특성 분석을 하는 것을 바탕으로 이후에 예측 모델을 학습시킬 것입니다.
chart(train, 'Sex')
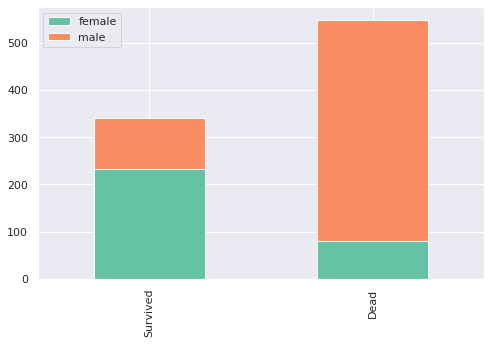
이 그래프는 성별에 따른 분류입니다. 여성과 남성만 비교하면 되는데, 여성은 생존률이 매우 높은 반면, 남성은 사망한 사람이 훨씬 많다는 것을 관측할 수 있습니다. 사고 당시에 남성보다는 여성을 우선적으로 살린 것으로 보입니다.
chart(train, 'SibSp')
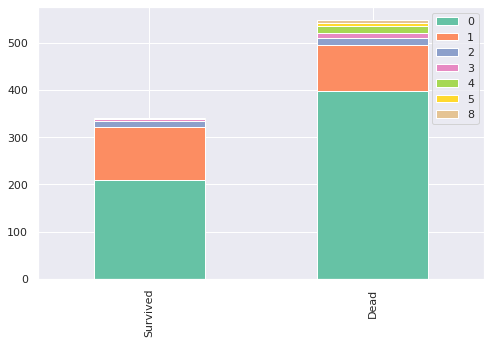
이 그래프는 자매와 배우자의 수에 따라 도시한 그래프입니다. SibSp 값이 0인 사람보다는, 비율상 1이나 2인 사람들이 더욱 많이 생존했다는 것을 확인할 수 있습니다. 하지만 3 이상부터는 잘 보이지 않아서 추가적인 확인이 필요할 것 같습니다.
한번 확인해보겠습니다.
temp = train[(train['SibSp'] > 2)]
chart(temp, 'SibSp')
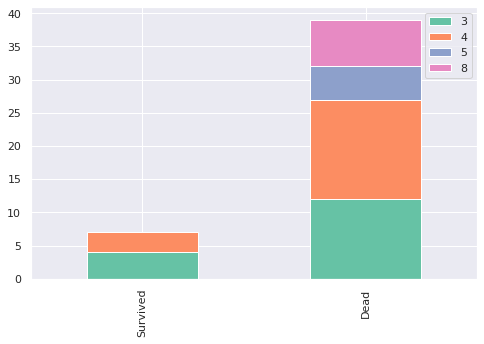
확인해보니 SibSp 값이 3 이상인 사람들은 생존율이 높지 않다는 것을 확인할 수 있습니다.
chart(train, 'Embarked')
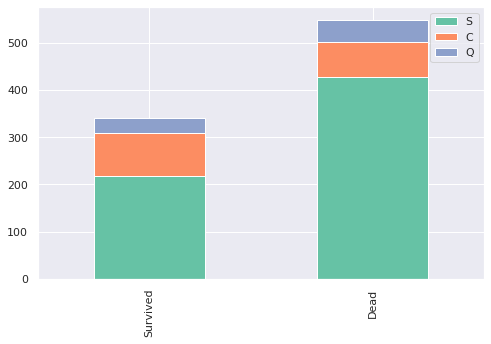
이번에는 승객별 탑승지에 따른 생존율입니다. 그저 탑승지의 차이라기에는 생각보다 차이가 많이 납니다. 지역별로 부유한 도시와 가난한 도시가 있을수도 있을 것 같습니다. 탑승지별로 1등석, 2등석, 3등석의 수를 한번 확인해보겠습니다.
S = train[train['Embarked'] == 'S']['Pclass'].value_counts()
C = train[train['Embarked'] == 'C']['Pclass'].value_counts()
Q = train[train['Embarked'] == 'Q']['Pclass'].value_counts()
df = pd.DataFrame([S, C, Q])
df.index = ['S', 'C', 'Q']
df.plot(kind='bar', stacked=True)
<matplotlib.axes._subplots.AxesSubplot at 0x7f23d6b214d0>
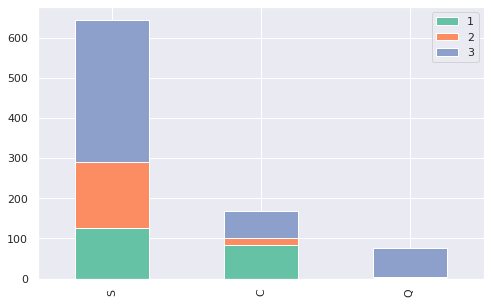
확인해보니 1등석의 비율이 탑승지별로 다른 것을 확인할 수 있습니다. Embarked가 C인 사람들은 1등석 비율이 거의 절반에 육박합니다. 이는 전 그래프에서 탑승지가 C였던 사람들의 생존률이 거의 50퍼센트에 가깝게 나왔다는 것에 큰 영향이 있을 것 같습니다.
이렇게 타이타닉 문제에 대한 데이터 분석을 해보았습니다. 다음 글에서는 Feature Engineering을 해보겠습니다. 감사합니다!
댓글남기기